Nama Kelompok
Edy Prasetyo(52411324)
Haries Yoga Pratama
Raden Moch Ryansah
Syatria Babullah (56411992)
Tentang Aplikasi
Edy Prasetyo(52411324)
Haries Yoga Pratama
Raden Moch Ryansah
Syatria Babullah (56411992)
Tentang Aplikasi
Aplikasi
yang kelompok kami buat akan menjadi alternatif pemecahan masalah yang selama
ini masih terjadi pada sebuah aplikasi berbasis pengenalan suara, masalah
tersebut adalah aplikasi berbasis pengenalan suara masih mengembangkan
bagaimana cara supaya aplikasi pengenalan suara tersebut dapat bersifat adaptif
pada lingkungan yang berisik(banyak mengandung noise). bahkan aplikasi seperti
siri(apple) dan google now(google) pun masih terus mengembangkan aplikasinya
dapat tahan terhadap lingungan yang berisik. aplikasi yang kelompok kami buat
adalah aplikasi preprocessing yang berguna sebagai filtering suara agar mampu
bertahan pada lingkungan yang berisik menggunakan bahasa pemogramam matlab.
Latar
Belakang Masalah
Bunyi atau
suara didefenisikan sebagai serangkaian gelombang yang merambat dari suara
sumber getar sebagai akibat perubahan kerapatan dan juga tekanan udara
(Gabriel, 1996). Suara merupakan salah satu media komunikasi yang paling umum
digunakan manusia, kualitas suara dapat terganggu bila lingkungan sumber suara
banyak mengandung noise yang melatarbelakangi informasi suara tersebut.
Rekaman
suara yang terdistorsi noise menyebabkan terganggunya proses pengenalan suara
terutama pada rekaman pembicaraan, karena penurunan kualitas suara yang
dikehendaki, sehingga perlu adanya perbaikan kualitas sinyal suara sebelum
dilakukan proses pengenalan suara.
Noise gate
telah diimplementasi dengan mendeteksi ambang batas bawah dan atas pada sinyal
suara, ketika level sinyal suara berada dibawah ambang batas bawah selama
durasi penahanan maka sinyal akan dilemahkan ke nol dan dibangkitkan lagi saat
waktu serang dan ketika level sinyal suara berada diatas ambang batas atas
selama durasi penahanan maka sinyal akan diperkuat sampai waktu rilis(Gerald
Leung, 2008).
Terdapat 4
macam klasifikasi filter dalam audio signal processing diantaranya low pass
filter, band pass filter, band stop filter dan high pass filter. Low pass
filter memungkinkan frekuensi yang berada di bawah batas dapat lolos tanpa
distorsi dan terjadi pelemahan pada frekuensi yang berada di atas batas(Dagmawi
Mallie, 2014).
Pada
penelitian oleh(G. Saha Dkk, 2011)dilakukan penelitian tentang seberapa efisien
penggunaan metode untuk silence removal menggunakan metode Probability Density
Function dengan Linear Pattern Classifier dibandingkan dengan Zero Crossing
Rate (ZCR) and Short Time Energy (STE). Metode yang diangkat dalam penulisan
ini adalah metode noise gate untuk meredam bagian yang hanya mengandung noise
dan low pass filtering untuk menghilangkan high frequency noise serta metode
probability density function(PDF) dan linear pattern classifier(LPC) untuk
menghilangkan bagian yang tidak bersuara(silence).
Audio
signal processing(pengolahan suara) adalah suatu bentuk proses/serangkaian
proses untuk memanipulasi sinyal dengan input suara(audio) yang
ditransformasikan menjadi suara lain sebagai keluarannya dengan tujuan
tertentu. Pengolahan suara dilakukan untuk memperbaiki kualitas data sinyal
suara digital agar lebih mudah diinterpretasikan oleh sistem pendengaran
manusia.
Landasan
Teori
a.
Speech Recognition
Speech
Recognition atau disebut juga dengan Automatic Speech Recognition atau dalam
Bahasa Indonesia adalah pengenalan suara otomatis atau pengenalan ucapan.
Speech Recognition mengkonversi kata-kata untuk teks. Istilah "pengenalan
suara" kadang-kadang digunakan untuk merujuk ke sistem pengenalan yang
harus dilatih untuk pembicara. Speech Recognition dapat menyederhanakan tugas
penerjemah pidato.
Pengenalan
ucapan adalah solusi yang lebih luas yang mengacu pada teknologi yang dapat
mengenali pidato tanpa ditargetkan pada pembicara tunggal seperti pusat
panggilan sistem yang dapat mengenali suara yang berubah-ubah.
Aplikasi
pengenalan ucapan termasuk pengguna antarmuka suara seperti panggilan
suara (misalnya, "Call home"), call routing (misalnya, "Saya
ingin membuat collect call"), domotic kontrol
alat, pencarian (misalnya, menemukan podcast di mana tertentu Kata-kata itu
diucapkan), sederhana entri data (misalnya, memasukkan nomor kartu kredit),
persiapan dokumen terstruktur (misalnya, sebuah laporan
radiologi),-untuk-pengolahan teks pidato (misalnya, kata
prosesor atau email),
danpesawat(biasanya
disebut Input
langsung suara ).
b.
Speech Syntesis
Speech
synthesis merupakan pelengkap dari speech recognition. Ide agar dapat berbicara
dengan komputer merupakan hal yang menarik bagi banyak user, khususnya bagi
mereka yang tidak bisa komputer.
Masalah
yang ada pada speech synthesis:
· User
sangat sensitif terhadap variasi dan informasi bicara. Sebab itu mereka tidak
dapat mentolerir ketidaksempurnaan pada speech synthesis.
· Output
dalam bentuk suara (spoken output) tidak dapat diulang atau di browse dengan
mudah.
·
Meningkatkan noise (berisik) pada lingkungan kantor. Atau bila
menggunakanheadphone akan meningkatkan biaya.
Lingkungan aplikasi speech synthesis:
Lingkungan aplikasi speech synthesis:
· Bagi
tuna netra, speech synthesis menawarkan media komunikasi dimana merekamemiliki
akses yang tidak terbatas.
·
Lingkungan dimana visual dan haptic skill user sedang terfokus pada hal lain.
Contohnya signal bahaya pada aircraft cockpit.
NON-SPEECH
SOUND
Digunakan sebagai alarm dan warning, atau status information. Penampilan informasi yang redundan dapat meningkatkan kinerja user.
Contohnya, user dapat mengingat suara yang mencerminkan icon tertentu, tapi bukan tampilan visualnya.
Digunakan sebagai alarm dan warning, atau status information. Penampilan informasi yang redundan dapat meningkatkan kinerja user.
Contohnya, user dapat mengingat suara yang mencerminkan icon tertentu, tapi bukan tampilan visualnya.
Ujicoba
Dan Hasil
Berikut
adalah tampilan aplikasi filtering suara pada lingkungan yang berisik yang
telah kelompok kami buat yaitu dengan memotong bagian yang memiliki banyak
noise serta meredam high frekuensi.
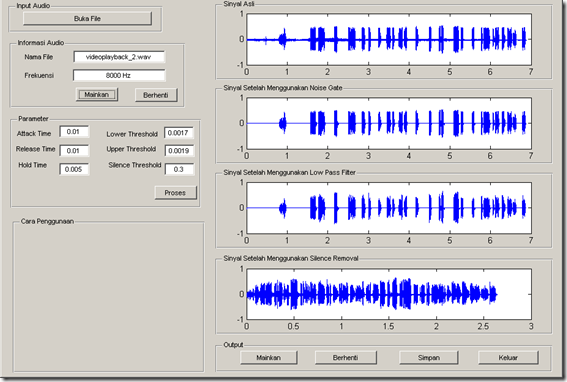
dari
gambar tersebut diketahui bahwa bagian diam(silence part) ikut terpotong
dengan metode ini sehingga yang tersisa hanya bagian penting dari source suara.
hasil tersebut dapat digunakan sebagai input pada aplikasi pengenalan suara
sehingga akan meningkatkan akurasi dari pengenalan suara tersebut.
Tidak ada komentar:
Posting Komentar